What is SelfHostLLM?
Calculate GPU memory requirements and max concurrent requests for self-hosted LLM inference. Support for Llama, Qwen, DeepSeek, Mistral and more. Plan your AI infrastructure efficiently.
Problem
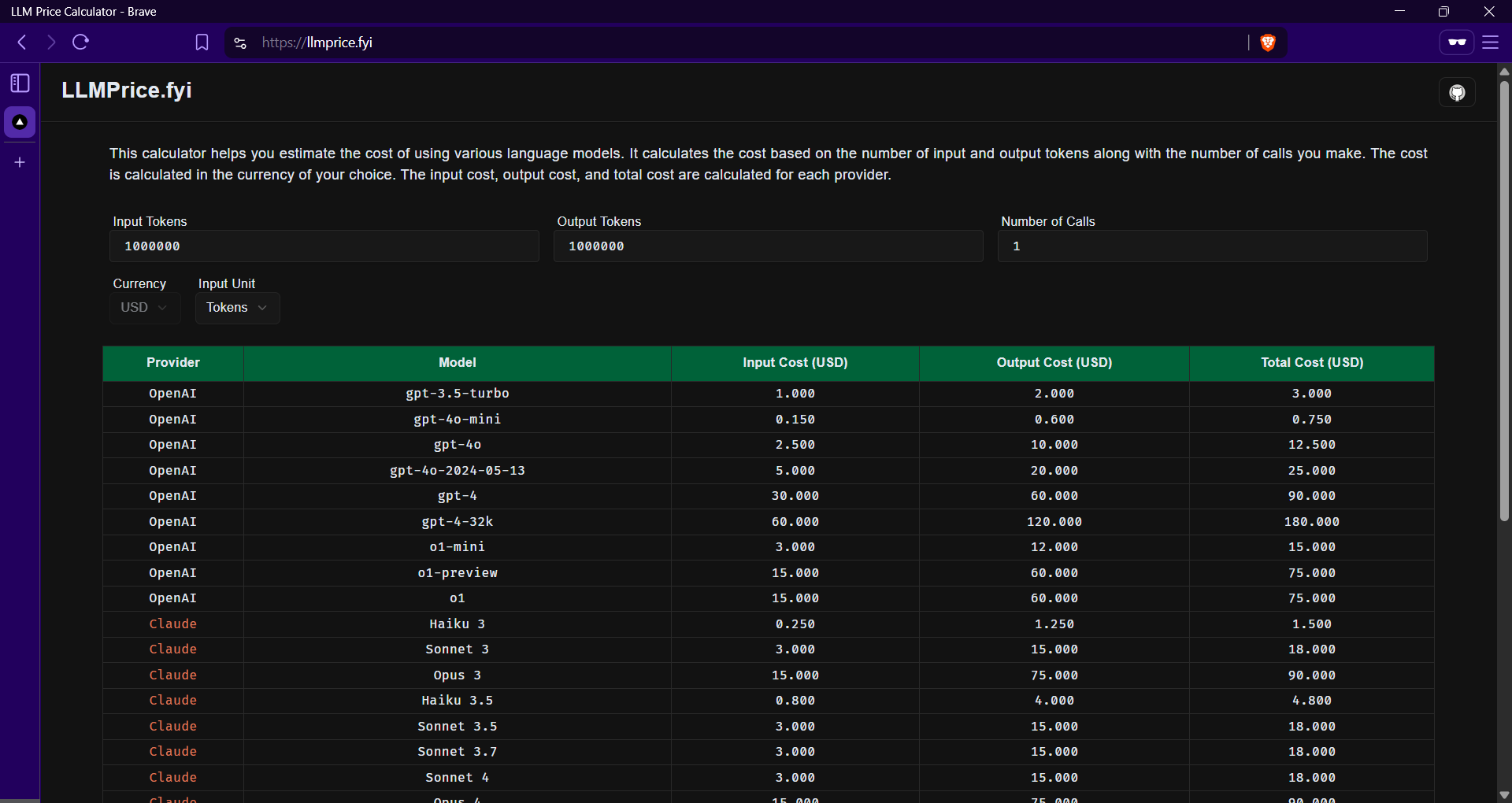
Users need to manually estimate GPU memory for self-hosted LLMs, leading to inefficient resource allocation, underutilization/overprovisioning, and inaccurate concurrency planning.
Solution
Tool to calculate GPU memory requirements and max concurrent requests using model parameters (e.g., model type, precision, context length), supporting Llama, Qwen, and Mistral for infrastructure planning.
Customers
AI Infrastructure Engineers, DevOps teams, and CTOs managing self-hosted LLM deployments.
Unique Features
Model-specific calculations, concurrency optimization guidance, and support for quantization/precision settings.
User Comments
Saves time in GPU allocation planning
Accurate predictions for LLM deployments
Essential for cost-effective infrastructure scaling
Simplifies model hosting decisions
Lacks integration with cloud billing APIs
Traction
Launched 2024, 1.2k+ ProductHunt upvotes, featured on AI/ML newsletters, used by 500+ companies (per website claims).
Market Size
Generative AI infrastructure market projected to reach $50.9 billion by 2028 (MarketsandMarkets).